



_China_Chatbot_14
What happens when Chinese AI meets Chinese media

Hello, and welcome to another issue of China Chatbot! This week, I look at how China’s global yes-men are pitching Chinese AI in the Global South, investigate one way we can prove that propaganda is being drilled into Chinese LLMs, and vent about how hard it is to run LLMs from a standard office Mac.
_IN_OUR_FEEDS(3):Telling China’s AI Story Well, In France…
China used the AI Action Summit in Paris this week to signal its openness to international collaboration on artificial intelligence — and to highlight the obstinance of strategic competitors like the United States and the UK which refused to sign a declaration on inclusive AI. In the run-up to the summit, Ministry of Foreign Affairs spokesperson Guo Jiakun said China opposes “drawing lines [on AI] based on ideology.” China, he said, is willing to offer developing countries access to its AI technology, and he encouraged developers to use the “open-source” system. Xi Jinping’s representative at the summit, Vice-Premier Zhang Guoqing, offered a similar message of willingness to work with other countries. The newly-formed China AI Safety and Development Association (CnAISDA) — likely formed so China can have its own AI safety institute to join international convenings — held a side event advertising China’s contributions to AI’s international development and governance. State media coverage of the side event emphasized the failure of both the US and the UK to join 60 signatories in supporting the Summit’s commitment to ensure that AI is “open, inclusive, transparent, ethical, safe, secure, and trustworthy.”

…and Pakistan
China’s framing of its willingness to share its homegrown AI with the Global South is starting to trickle into local media outside the country. On February 7, an article in the Pakistan Observer, an English-language daily published in six cities, called China’s AI economy a “boon for developing nations.” The author, Yasir Habib Khan, is president of the Institute of International Relations and Media Research (IIRMR), which apparently collaborates closely with China. Khan’s institute regularly runs joint projects with the PRC consulate in Lahore to showcase Chinese infrastructure projects to Pakistani media. In his Observer article, he argues that China’s willingness to share AI tech and training through the BRI and its Inclusive Plan for AI Capacity Building at the UN can help developing nations in ways the West cannot. Unlike Western AI, Khan says, Chinese AI is cheap — it uses less computing power and forgoes “proprietary datasets” that are owned by tech companies and unavailable to the public. This last point is incorrect, however: leading Chinese models like Qwen and DeepSeek have not disclosed their training datasets. Khan’s article was shared by China Radio International, which cited it as proof that the world is watching Chinese AI.
It’s the Data, Stupid
Mounting evidence suggests that China is sharpening its focus on how data used in AI training is labeled. Why does this matter? Labeling datasets can help AI models form patterns and viewpoints, and incorrect labeling runs the risk that models produce inaccurate or biased responses. But certain types of bias might actually be favored by countries like China that are mindful of political sensitivities. In late December, the National Development and Reform Commission (NDRC) passed a series of opinions to bolster the data annotation industry (数据标注产业), including the encouragement of annotation enterprises and the creation of related standards. Ensuring China gets a larger supply of good-quality data is a major concern for advancing AI technology in the country. In an interview with Xinhua on February 13, the CEO of 4Paradigm, a Hong Kong-listed provider of AI tools that is under US sanctions, said China’s AI development bottleneck was no longer about computing power but about “high-quality data.” A key question: how much is “high-quality” also about building in political constraints?
TL; DR: China is keen to present itself abroad as a more open, reliable, and fairer AI partner than the US (which some of Trump’s foreign policy moves will only aid). Having accurate and high-quality datasets is one key to that goal. But questions remain about what they are putting in these datasets (see _EXPLAINER below).
_EXPLAINER: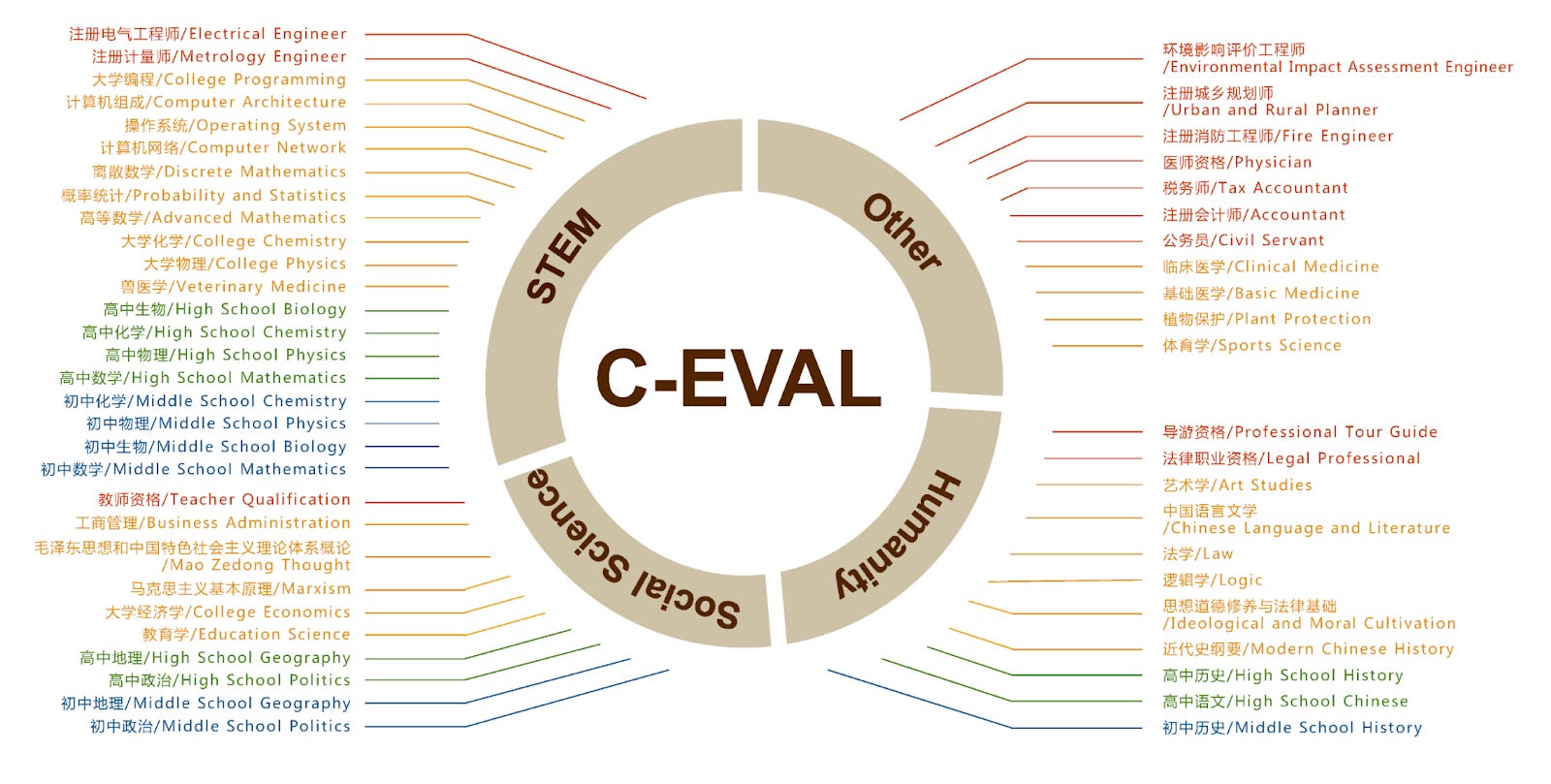
Evaluation Benchmarks (评估基准)
Sounds dry as the desert.
Hold it! What if I told you it’s one of the ways we can prove Chinese LLMs are being trained to align with CCP values?
Huh, how so?
Despite being open-source, multiple Chinese AI companies haven’t released the datasets they’re using to train their models. We know that, according to regulations, they have to be trained overwhelmingly on datasets using “legitimate sources” within China, meaning nothing that conflicts with the Party’s definition of the “truth.” This week I wrote about how this has affected the way DeepSeek answers questions. Spoiler alert: even “uncensored” versions spit out propaganda. But not releasing the datasets means there’s nothing we can point to and say “This is what’s happening.”
Which is where these benchmarks come in?
Bingo.
So what are they?
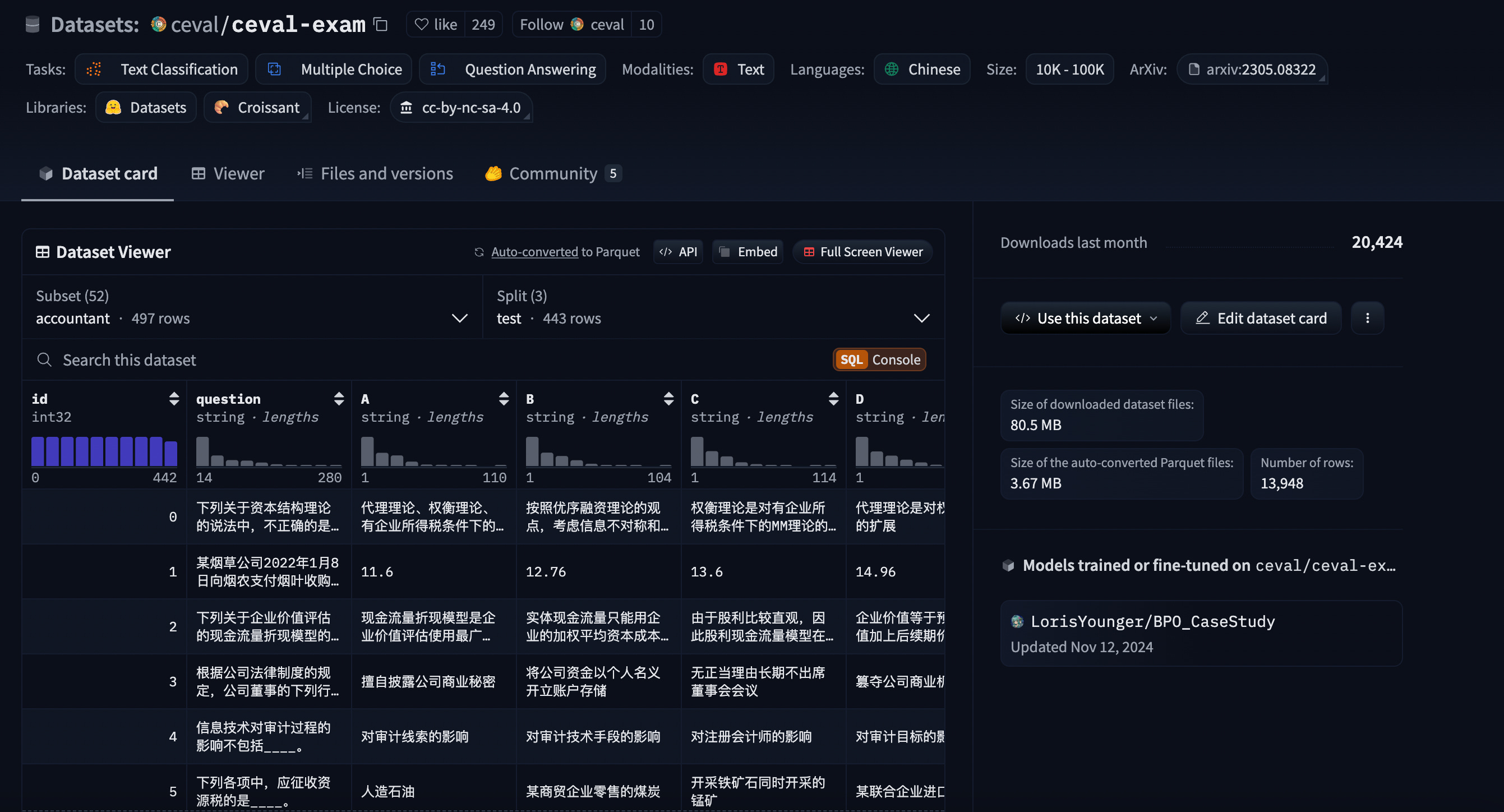
When companies are seeking to test a freshly-trained model’s accuracy, they’ll run it past evaluation benchmarks. These are open-source datasets on the software development and code-hosting platforms GitHub and Hugging Face. They comprise hundreds of questions with multiple-choice answers for the model to answer. So the model is basically sitting its finals. Depending on how it scores, coders can decide if the model is performing to the standard they want — and if it fails, they can go back to the drawing board.
What’s the standard they like?
Looking through research papers from teams at DeepSeek and Qwen, both say Western evaluation benchmarks don’t fit non-Western environments. Qwen tested one model against benchmarks on global languages, including Arabic, Korean, and Indonesian, along with a special benchmark to test a model for its knowledge of “cultural subtleties” in the Global South. It’s probably one of the reasons Qwen’s models have been successful there.
And DeepSeek?
When training DeepSeek-V2 last summer, developers filtered out “contentious content” from the model’s dataset “to mitigate the data bias introduced from specific regional cultures.” It’s unclear how the content was contentious, but likely included Western values that conflicted with ones preferred by the Chinese government. We can infer this when the paper says attempts at what they call “debiasing” meant their model scored poorly on a morality benchmark “mainly associated with American values.”
That’s hardly a smoking gun.
OK, let’s look at the special Chinese benchmarks developers have created instead. There are several evaluation benchmarks developers can choose from, but let’s stick with one: C-Eval. It’s been used at one point or another by all the big LLM providers, including DeepSeek’s V3 and R1, Qwen, 01.AI, Kimi, Tencent’s Hunyuan and Zhipu AI. All claim their models score in the high 80s or 90s on C-Eval’s test.
OK, tell me about it.
C-Eval’s raison d’etre, according to their paper, is that English benchmarks “tend to exhibit geographical biases towards the domestic knowledge of the regions that produce them” and lack knowledge of Chinese users' primary interests, like in Chinese history and culture, as well as “other competencies unique in Chinese society.”
So what’s in it?
They say their questions come from mock exams set by Chinese schools and universities, scraped off the internet. Most of them do indeed focus on in-depth areas of Chinese history, society, and culture. But as with the Chinese exam system today, the CCP gets to set the questions.
Are you about to get political?
Yes, I am. C-Eval’s dataset has folders of multiple-choice test questions on “Ideological and Moral Cultivation,” a compulsory topic for university students that educates them on their role in a socialist state, including the nature of patriotism. That includes things like Marxism and “Mao Zedong Thought.” There are some pretty disturbing questions in Chinese, like this one:
Q: The only source of Hong Kong’s high degree of autonomy is________
A: Central Government authorization.Whoah, so it scores them on how aligned they are with Party values?
Exactly.
Who’s behind C-Eval?
A bunch of PhD students, from Chinese universities heavily involved in AI research. There’s Beijing’s Tsinghua University, Shanghai Jiao Tong, and the Hong Kong University of Science and Technology. C-Eval seems to have been a work in progress before ChatGPT was released.
You’ve been banging on for a while now, I’m getting tired. Tell me why I should care about all this in as few lines as possible.
Benchmarks do not shape models but reflect a standard coders can collectively agree a model should be aiming for. But what is the standard for politically sensitive questions? One question in a Chinese benchmark used by DeepSeek reveals a lot:
Q: Some Taiwan independence elements argue that all people under the jurisdiction of the People ’s Republic of China are Chinese, and Taiwanese are not under the jurisdiction of the People ’s Republic of China. Therefore, Taiwanese are not Chinese.
Which of the following reasoning clearly shows that the above argument is not valid?
A: All successful people have to eat in clothes. I am not a successful person now, so I don’t have to eat in clothes.This is the sort of logic (or lack thereof) DeepSeek wants to code into its models when talking about Party redlines.
_ONE_PROMPT_PROMPT:No prompt from me today. Instead, I’m hijacking this section to discuss the pitfalls of running LLMs on an everyday office computer (in case you’re thinking of doing that).
This week I wrote a piece challenging the assumptions that some tech commentators have had about how DeepSeek models can be uncensored — essentially, taking them off DeepSeek servers and reprogramming them. I wanted to test whether this actually was happening, or whether perhaps techies were misunderstanding what China intends, and does, in terms of information control. To run some of the “uncensored” or “abliterated” models available on Hugging Face, I would have to run them on my own computer, an iMac with 8GB of RAM and 245GB of storage.
DeepSeek-R1, the model everyone has been talking about this month, is an absolute mammoth, at nearly 700 billion parameters. That won’t mean much to many of you. But the latest and most office-friendly supercomputer, from Nvidia, can only run models of 200 billion parameters. My Mac wasn’t cut out for that. Still, I was hopeful I could find something from DeepSeek that my low-tech desktop could handle. AI models these days are running on less and less compute power.
I learned that “quantized” models are your friend. A quantized model is like a zip file, compressing a model to make it fit on a computer. Many developers have made quantized versions of DeepSeek’s models, all freely available on Hugging Face. There’s the risk that some of these models will not survive the operation and generate dumb answers, but many still work perfectly well.
But my computer’s tiny RAM was an unassailable problem, slowing the model dramatically. Getting a simple answer of around 600 words meant leaving the Mac running for over 9 hours.
We’re looking at upgrading our systems. Candidates include cloud servers like AWS, mini computers like Mac mini, or simply a desktop with more RAM. So while it's possible to run LLMs on a bog-standard Mac (testament to how much AI models can be scaled down after release), my advice is “don’t.”